Join thousands of other open-source enthusiasts and developers in the Open Source Hub Discord server to continue the discussion on the projects in this week's email!
🎙️ Interview With Michael of git-bug: an offline-first bug tracker
Michael and his Cat
Hey Michael! Thanks for joining us! Let us start with your background. Where are you from, where have you worked in the past, how did you learn to program, and what languages or frameworks do you like?
Hi, Michael, from France. I started learning programming quite early at the age of … 13 (maybe), when I got very intrigued by how computers worked and all that magic. Unfortunately, I did that by picking a book about C++, getting nowhere about pointers and giving up for a few years. That path got revived later with those TI calculators and their Basic programming language, coupled with being bored in school.
I became quite autodidact and went on exploring various topics and languages. Later I got impressed and envious about those people doing crazy things in the Google Summer of Code program. I applied a few times and got selected to work on GIMP to implement the cage deformation tool. That was a quite foundational experience as it got me in contact with very talented individuals who taught me how to maintain software and open source. More than that, it forced me to improve and change my ways of working, going from toy sized programs to a 20 years old one you just can’t entirely understand: how to read code, find information, leverage tools like debuggers, and safely manage the chaos.
During my professional career, I worked on video games, some more mundane banking stuff, and I’m now tech lead on IPFS services at Infura.
Nowadays I work almost exclusively with golang, as it strikes a very nice balance of productivity, performance and more importantly a no-bullshit everyday workflow (yes I’m looking at you NodeJs).
What’s your most controversial programming opinion?
UUIDs are overrated. They are often picked up because they are available in most databases, but really most of the time you just want some random bytes, or even those random yet sortable IDs like KSUID.
What is your favorite software tool?
The jetbrains suite of IDEs. I love when computers do what they do best and free me of checking thousands of things, leaving me to work on the real meat of the problem at hand. They are doing such a good job that they even end up teaching me how to do better.
What is your favorite book and why?
“The Pragmatic Programmer” by David Thomas, Andrew Hunt, and “Designing Data-Intensive Applications” by Martin Kleppmann deserve their praise.
My future favorite book is the one that will teach in an understandable way those somewhat confidential techniques like cryptography, hashing, XOR based tricks, Bloom filters and friends, CRDTs … They are super powers of software design, and I wish we would have some “design pattern” book about them.
If I gave you $10 million to invest in one thing right now, where would you put it?
Git-bug of course 🙂. Not so sure that would see a return, but I believe we collectively deserve better tools, and it’s a bit silly that we keep having our own data kept in the custody of someone else. A social network based on the same principles would be great as well.
Why was Git-bug started?
In engineering school, I became quite interested with P2P technologies, real distributed networks and their societal implications: taking back control of your digital life, avoiding mass profiling, mass advertising and all the worse stuff that Edward Snowden told us about. They are also great techniques, borderline magic when you don’t know how they work.
So I went on my way to build such a thing, aiming to make a file sharing application for everyday people. The typical usage would have been sharing private data (say, holiday pictures) between your social circle, and avoiding being forced to use Facebook and friends because only that works. Something between email, twitter and bittorrent. Extended further, you could have public sharing by artists without requiring a platform, with crypto signature and so on.
Point is, that failed. Then I discovered IPFS which was basically what I wanted and not made by naive idiots like me. I restarted my project around IPFS, and failed again due to deep architecture issues on my side and some immaturity of that tech at that time.
Yet, I learned a lot from my attempts and the community around those projects. Not only on the technical side, but also on product design, UX and even marketing. When I got fed up with hitting the same wall on that project, I remembered that idea (not mine btw) of a distributed bug-tracker. From all I learned, I knew I could do better and fix the shortcoming of previous attempts on that idea. I worked on it full time for a month, got most of the features fleshed out (conflict resolution, CLI, TermUI, webUI), published it, got 4000 stars and a job.
Were you hired by Infura to work on IPFS based on the work you did for git bug?
Yes, plus my previous experience with IPFS. In the first post on hacker news that got so much traction I said I was looking for a job. That got me on their radar.
How does Git-bug work?
Let’s start with what git-bug is. The same way git has a full copy of all revisions of your code, git-bug aims to have a full history of the tickets of your project. That makes it offline-first, very fast, prevents vendor lock-in, integrates with your tooling and workflow … I also want to extend that to pull-requests, kanban boards and so on.
When those tickets are exchanged with push/pull on a git remote, git-bug needs to handle conflict resolution. To do so, instead of storing the current state, git-bug will store a series of immutable operations on that state : create, add a comment, close ….
When a ticket is read, we apply those operations in order to compute the current state. This is a common idea in CRDTs and other similar techniques.
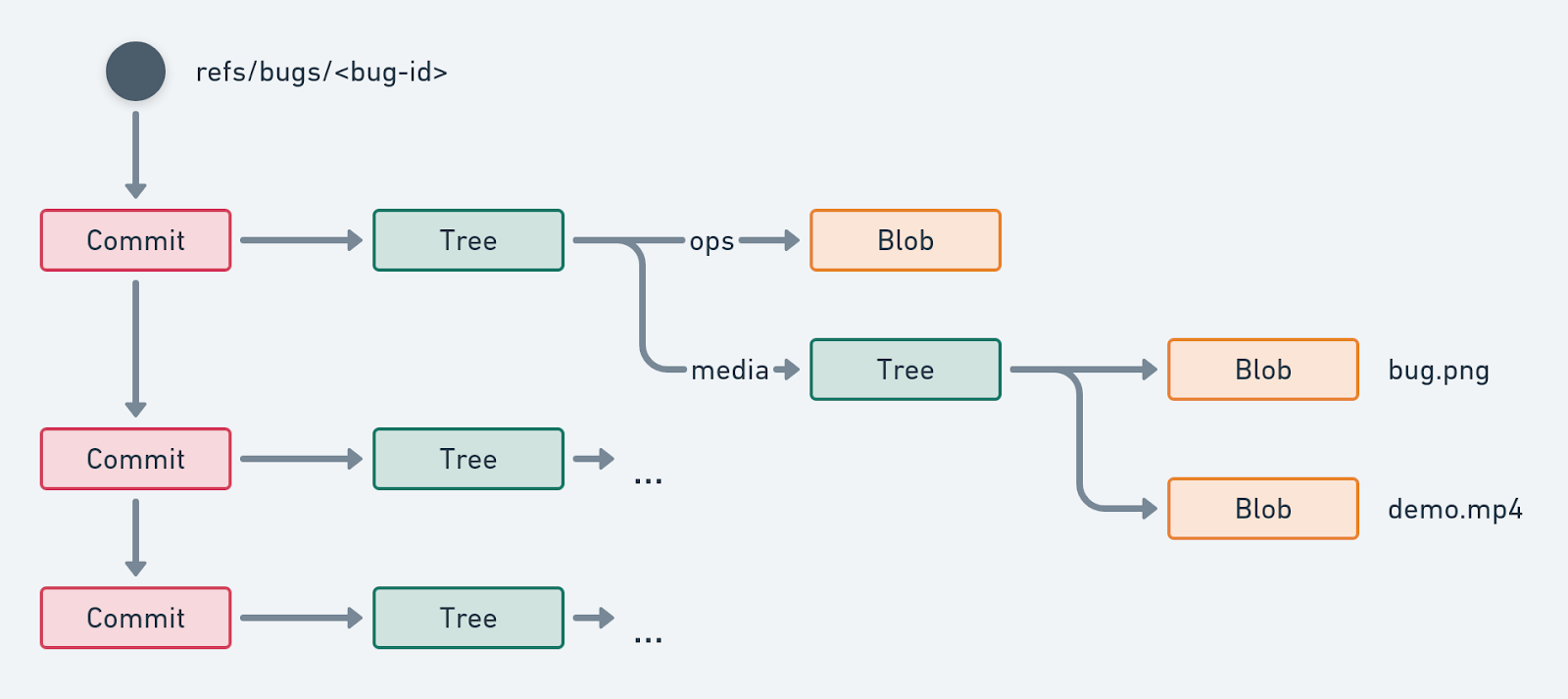
One key aspect though is that git-bug does NOT pollute your normal code with files. Instead, it’s using git’s content addressed database (.git/objects) and the base data types: Blobs, Tree, Commit, Reference. Those operations are serialized as JSON, stored in a Blob, then assembled into a graph of Commits with a Reference pointing to the head. If two users add some operations on different machines then combine their graphs we get branches. That graph topology, coupled with some logical clocks gives us a deterministic ordering of operations.
I had been looking for a long time for a modernized programming language, without the difficulties of C, the crazy complexity of C++ or the madness in the Java/Javascript ecosystems. One where you would not spend days on how to compile or test. I then discovered Go through the IPFS project and I got enlightened. Things are really so much simpler and powerful. That language made me a more productive engineer, while steering me away from quite a lot of design mistakes.
What is the most challenging problem that’s been solved in Git-bug, so far?
Two equally challenging things: conflict resolution, and going from prototype to robust and usable result.
Conflict resolution has been terribly challenging as it required me to dig into this side of computer science where people talk like you know what a join-semilattice is. You drown very quickly into overly correct formalism, while simple insights are a rare thing. The first conflict resolution algorithm of git-bug was enforcing a purely linear series of operations with rebase-like merging. That happens to fail in truly p2p topology, so I ended up changing that to a real DAG with branches as I described. But even now I can’t fully shake the feeling that there might be some oversight in there. Yet it works so I guess that’s what matters.
The first version of git-bug took me one month and 200 commits. Now clocking at 2000 commits, there is essentially the same features set but a huge amount of work has been done to make it fast, robust, correct and extensible.
What was the most surprising thing you learned while working on Git-bug?
Not necessarily a thing I learned, but I’m still quite surprised just how well things turned out to be. Product and technical design just came in place very early and almost naturally. The more you look, the more it makes so much sense, and the external recognition came very quickly. For someone that failed so much before it’s unexpected ;-)
What is the best way for someone to contribute to Git-bug?
As mentioned in the Readme, this project has grown bigger than I can handle by myself, especially with a day job. I'm looking for people to help on or maintain part of it:
each bridges (go)
the terminal UI (go)
the web UI (Typescript/React/GraphQL)
But really, as git-bug targets a population of software engineers, I hope we can collectively make it OUR tool, improve it and adapt it to whatever quirk of our workflow, yet have that common way to work together. Something that classic forges are not even trying to do.
What are you most proud of?
One thing I’m quite proud of, is that one can now quite easily create a new entity type (let say: pull-requests) and have for free all the conflict resolution, storage, cache and indexing already figured out. That has so much potential for git-bug of course, but also for a large class of tools. What if git was not only a DCVS, but also a database and transport for distributed apps?
Where do you see the project heading next?
There are two major directions I want to go: more entities and a public portal for projects.
The first one is adding support for more things: pull-requests, kanban, … This is largely underway with the core gradually getting ready to accept it.
The second one is critical for any project, open source or not: you want the public or non-technical peoples to be able to open issues and participate in the discussion without having git push rights. For git-bug that would take the form of extending the webUI to accept external authentication (say, the Github one). That means that a project could have a git remote, and run the webUI publicly on the internet. You would then get your very functional forge trivially, running from a single binary
Want to join the conversation about one of the projects featured this week? Drop a comment, or see what others are saying!
Interested in sponsoring the newsletter or know of any cool projects or interesting developers you want us to interview? Reach out at osh@codesee.io or mention us @ConsoleWeekly!